Generative Recommenders
Generate rather than retrieve the recommendation

Introduction
Recommendation systems have evolved significantly from their early iterations to become sophisticated tools central to modern digital experiences. Initially, systems relied on basic collaborative filtering and matrix factorization by modeling latent user-item interactions. The advent of machine learning and deep learning revolutionized the field further, enabling complex pattern recognition through neural networks, NLP, and hybrid models that blend techniques for richer insights. More recently, Large Language Models (LLMs) have drawn lot of attention due to their generalization and data efficiency. LLMs can potentially transform recommender systems by moving beyond traditional collaborative filtering and matrix factorization.
In my previous work, I investigated the potential of LLMs for recommendation tasks. I studied the efficacy of LLMs for movie recommendation. I experimented with pre-trained small LLMs like Llama3.2 and Qwen2.5 models as well as fine-tuning them on labeled user engagement data for the task of predicting whether a user will like a given candidate movie based on their recent 10 watched movies. I did further experiments in fine-tuning LLMs for recommendation by increasing model size, adding user attributes, synthetic chain-of-thoght data generated by frontier models like GPT-4o, and GRPO-based RL fine-tuning. Results showed fine-tuned LLMs achieved competitive accuracy with fewer training examples than traditional approaches like matrix factorization and transformer neural networks, leveraging pre-trained knowledge for data efficiency. This highlights LLMs' adaptability for personalized recommendations when tailored to domain-specific tasks.
Generative Recommenders
Recommender systems typically retrieve items from an item corpus for personalized recommendations. Generative recommenders use generative models (e.g., transformers, VAEs, LLMs) to generate personalized recommendations by modeling user-item interactions as a sequence or latent distribution. Unlike traditional recommenders that retrieve items from a fixed catalog, generative models can synthesize new recommendations dynamically, adapting to user preferences in a more flexible and contextual way.
Generative recommenders offer several advantages:
Beyond Retrieval – Instead of selecting from a fixed catalog, they can synthesize novel recommendations, improving diversity and serendipity.
Personalization & Context Awareness – They capture complex user preferences and generate recommendations dynamically based on context, history, and intent.
Cold Start Handling – They can generate recommendations even for new users or items without relying on historical interactions.
Multi-Modal & Rich Representations – They can incorporate diverse data sources (text, images, metadata) to enhance recommendation quality.
Improved Sequence Modeling – Models like transformers capture long-term dependencies in user behavior better than traditional methods.
Current Work
In this work, I experiment with LLMs for generating recommendations. Generative recommenders based on large language models (LLMs) represent a shift from traditional retrieval and ranking approaches toward models that generate recommendations directly in natural language. These systems treat recommendation as a conditional text generation task, where the model outputs item suggestions (e.g., product names, article titles, content descriptions) based on user profiles, recent activity, or prompt context. I try to build a generative movie recommender.
In the prior study, I studied the efficacy of LLMs for movie recommendation where we designed a binary classification problem (akin to ranking workflow in traditional recommendation systems) to determine whether a given candidate movie would be watched by the user. The same MovieLens 1M dataset containing user ratings for movies is employed to train and validate models. Instead of the task of predicting whether a user will like a given candidate movie based on their recent 10 watched movies, the task here is to generate the next movie that the user will watch based on their recent 10 watched movies.
Generative Movie Recommender
To build a movie recommender, I use supervised fine-tuning (SFT) to teach the LLM to learn movie preferences from the historical data. Using the framework of the past work, I created a train dataset containing 84297 examples with input past 10 movies and label the next movie.
Training
Model: The Qwen2.5-7B-Instruct model is used as the base model.
Instruction Data: We construct an instruction dataset from the MovieLens which contains (instruction, response) pairs. The instruction contains the user’s last 10 watched movies and the response is the next watched movie. The instruction and the response are combined for training applying chat template to create prompts of the form:
<|im_start|>system
Based on a user's history of past watched movies, predict the movie the user is most likely to watch next.
<|im_end|>
<|im_start|>user
## User History:
- Watched the movie "Girl, Interrupted (1999)" of genre "Drama" and gave rating: 4.0
- Watched the movie "Titanic (1997)" of genre "Drama|Romance" and gave rating: 4.0
- Watched the movie "Back to the Future (1985)" of genre "Comedy|Sci-Fi" and gave rating: 5.0
- Watched the movie "Cinderella (1950)" of genre "Animation|Children's|Musical" and gave rating: 5.0
- Watched the movie "Meet Joe Black (1998)" of genre "Romance" and gave rating: 3.0
- Watched the movie "Last Days of Disco, The (1998)" of genre "Drama" and gave rating: 5.0
- Watched the movie "Erin Brockovich (2000)" of genre "Drama" and gave rating: 4.0
- Watched the movie "To Kill a Mockingbird (1962)" of genre "Drama" and gave rating: 4.0
- Watched the movie "Christmas Story, A (1983)" of genre "Comedy|Drama" and gave rating: 5.0
- Watched the movie "Star Wars: Episode IV - A New Hope (1977)" of genre "Action|Adventure|Fantasy|Sci-Fi" and gave rating: 4.0
## Target movie:
"<|im_end|>
<|im_start|>assistant
"Wallace & Gromit: The Best of Aardman Animation (1996)" of genre "Animation"<|im_end|><|im_end|>Training Set up: We used parameter-efficient fine-tuning method LoRA on instruction data created from the training data and evaluated on the test set. Effective batch size is 512, AdamW optimiser with LR 5e-5 and weight decay 0.01. As convention, we used a cosine learning rate scheduler with 5% warm up steps. We use 4-bit quantization and the Unsloth library for faster training on a single GPU. The LoRA rank is chosen to be 16 and the model is trained for 1 epoch.
Responses
Let’s look at the responses produced by the fine-tuned model.

The expected movie here is Bodyguard, The (1992) of genre Action|Drama|Romance|Thriller. One can argue the prediction is not way off given the past movies. The other predictions for the same input prompt were 'Speed', 'Rock, The', 'Lethal Weapon 2', 'Blow', 'Mission: Impossible', 'True Lies', 'Deep Blue Sea'
with genres
'Action|Crime', 'Action|Adventure', 'Action|Adventure|Thriller', 'Action', 'Action|Comedy', 'Action|Adventure|Romance', 'Action|Adventure', 'Action|Sci-Fi|Thriller', 'Action|Comedy|Crime', 'Action|Adventure|Thriller'
which match the actual movie.
Another example:
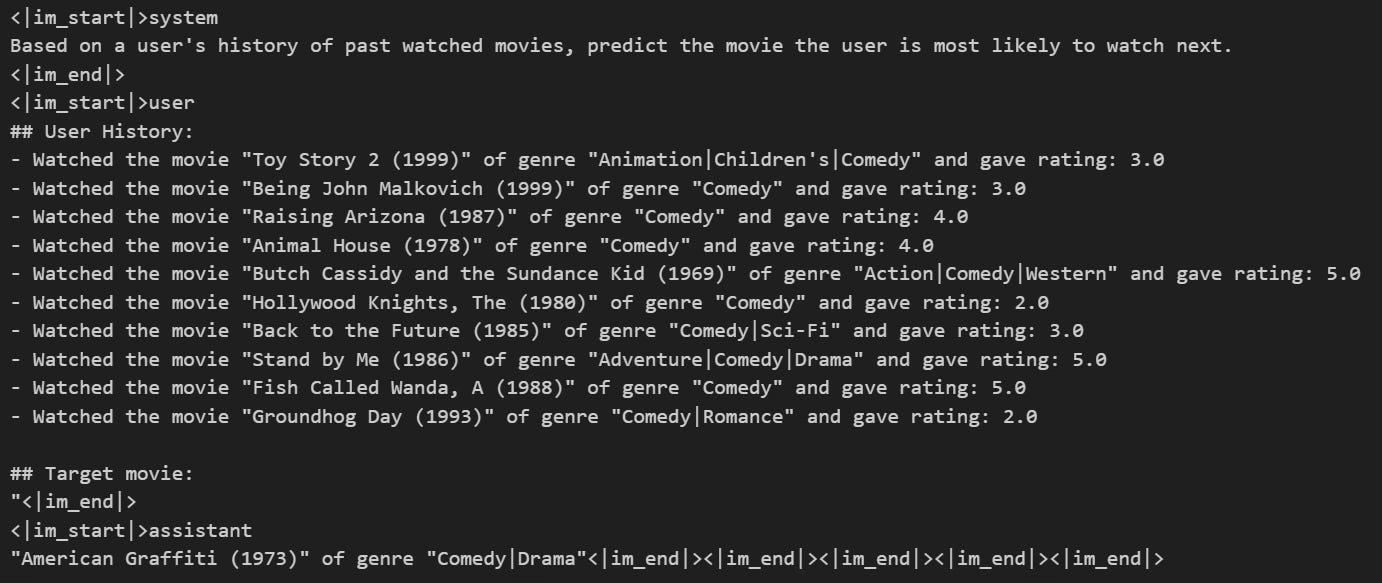
where the actual movie is Happy Gilmore (1996) of genre Comedy.
I interpret the qualitative assessment (‘vibe check’) of the generated responses as evidence reinforcing the efficacy of LLMs for recommendation tasks and the potential of generative recommendation systems as a research domain.
Evaluation
Evaluation of generative recommenders on historical data can be tricky. At inference, the model generates the recommendation as text. Now this generated text:
Might not be a movie title, though SFT should push the model towards generating movie names.
Can be a movie not in the corpus
Can be a movie from user’s past history since while training the model has access to only last 10 movies.
Can potentially have different formatting. Again, SFT should help mitigate this problem.
The evaluation strategy adapted in this work is “top-1 accuracy with negative sampling” (also sometimes referred to as “Hit Rate @1” or “Recall @1” when only one positive and k-1 negatives are evaluated per test instance). The recipe is the following:
For each test case i.e. (user, past_movies, target_movie) triplet,
Randomly sample 9 negative movies for the
useri.e., the movies that the user has not watched.Add the
target_movieto the negative samples to form a set of 10candidates.At inference, generate from the model based on the
past_movies.Call the generated movieoutput.Use a frontier LLM to extract the movie from the
candidatesthat is most similar to theoutput. The most similar movie is used as thepredicted_moviefor the test case.If the
predicted_movieis same thetarget_movie, it’s a hit; otherwise, it’s a miss.
The final metric is the fraction of hits over all test examples.
Similarity: I used GPT-4o model for extracting most similar movie from the candidates. Although, 4o-mini also gave similar results. The prompt used here is the:
One can also use a different notion of similarity e.g., using collaborative or content-based embeddings. LLMs can have variability during generation. A strategy I tried is to use temperature sampling to generate 5 completions, and then use the movie which is most similar to any of the completions as the prediction.
Results: There were 500 test cases, and the value of Recall@1 turns out to be 0.225 which admitedly is hard to interpret without any baseline numbers. I am working on an evaluation protocol along these lines, will share codes and more elaborate results soon. LLM inference is expensive too!
Conclusion
In this work, I adapted LLMs as generative recommenders by fine-tuning a pre-trained LLM to generate the movie the user is expected to watch next based on their past 10 watched movies. The model seems to be learning the behaviour. However, there are many gaps here. No comparison with other approaches was performed to quantify the performance of this method. Moreover, the model was trained only for 1 epoch. This is meant to be a PoC. I am working on a proper recommendation model with elaborate evaluation. Stay tuned!
If you find this work useful, I would appreciate if cite it as:
@misc{verma2025genrec,
title={Generative Recommenders},
author={Janu Verma},
year={2025},
url={\url{https://januverma.substack.com/p/generative-recommenders}},
note={Incomplete Distillation}
}
Great job