
Large Language Models for Recommender Systems II - Scaling
Do scaling laws extend to recommendation?

Introduction
Recommendation systems have evolved through paradigms like collaborative filtering, matrix factorization, and deep neural networks, with recent interest in transformer-based models. Large Language Models (LLMs) emerge as promising tools due to their world knowledge (learned from vast text corpora) and reasoning capabilities, enabling nuanced understanding of user preferences and contextual patterns (e.g., linking "dark comedies" to specific thrillers). However, traditional models like SVD (high precision, low recall) and SASRec (sequential self-attention for dynamic user behavior) remain strong baselines.
In a previous study, I investigated the potential of LLMs for movie recommendation by evaluating a fine-tuned Llama 3.2 1B model against traditional baselines (SVD, SASRec) on the MovieLens dataset. Using binary classification (like/dislike) based on user histories (last 10 engaged movies), it tested zero-shot, few-shot, and supervised fine-tuning (via LoRA) approaches. Results showed fine-tuned LLMs achieved competitive accuracy with 35x fewer training examples than SASRec, leveraging pre-trained knowledge for data efficiency. This highlights LLMs' adaptability for personalized recommendations when tailored to domain-specific tasks.
Scaling Laws
LLMs are often governed by scaling laws, which suggest that increasing a model’s size (and training data) typically leads to better performance on a range of language tasks. This relationship has been observed in models such as GPT, PaLM, Chinchilla, and LLaMA, where larger parameter counts improve perplexity, generalization, and data efficiency. The driving factor in this study is to determine if these scaling laws extend to down-stream tasks like recommendation and if the performance gains justifies the higher compute cost and inference latency. There are several factors that determine the success of scaling:
Data Quality: Larger models can take advantage of large and diverse data much more effectively. In scenarios where only small or homogenous datasets are available, the advantage of bigger models may not fully materialize.
Task Complexity: For tasks that require understanding complex context or subtle language cues, larger models typically learn more intricate patterns and deliver superior performance. If the task is straightforward, a smaller specialized model may do just as well.
Diminishing Returns: As models grow bigger, each additional increase in size or training data tends to yield smaller improvements in their performance. This effect often arises because easy-to-capture patterns are learned early on, while the remaining patterns are more complex or subtle, requiring disproportionate amounts of computation and data to attain marginal gains.
Current Work
In the prior study, I used small-scale language model, Llama 3.2 1B, which was a good choice to build a proof-of-concept. Furthermore, I fixed past 10 movies as input features, which allowed to focus on the efficacy of LLMs for the task. In this work, I scale up the system by experimenting on different model sizes as well as incorporating additional input features.
The same set up is used here: MovieLens 1M dataset containing user ratings for movies is employed to train and validate models. The task is to predict whether a user will like a given candidate movie based on their recent 10 watched movies. I conducted various experiments with supervised fine-tuning LLMs for this task borrowing the LoRA configuration from the earlier study. As before Precision, Recall, AUC-ROC, and Accuracy are used as metrics.
Scaling: Model Sizes
First experiment I conducted was to scale up the model by evaluating the performance of larger models beyond the 1B parameter baseline. I used the Qwen2.5 series of models for this experiment as it has models at varying sizes.
Recall, we constructed an instruction-following dataset from user–movie interactions in the MovieLens data. The prompt contains the user’s last 10 liked/disliked movies (titles) plus the target movie title. The response is “Yes” or “No”. The prompt looked as follows:
## Instruction:
Below is a user's history of likes and dislikes for movies, followed by a target movie. Predict whether the user will like the target movie or not. Only output the prediction as Yes or No.
## User’s history:
- Liked "Girl, Interrupted (1999)"
- Disliked "Titanic (1997)"
...
- Liked "Star Wars: Episode IV - A New Hope (1977)"
## Target movie:
"Wallace & Gromit: The Best of Aardman Animation (1996)"
## Response: Results: The first experiment investigated whether larger models provide tangible improvements for the recommendation task. Models of varying sizes are fine-tuned on the instruction data for 1 epoch each.
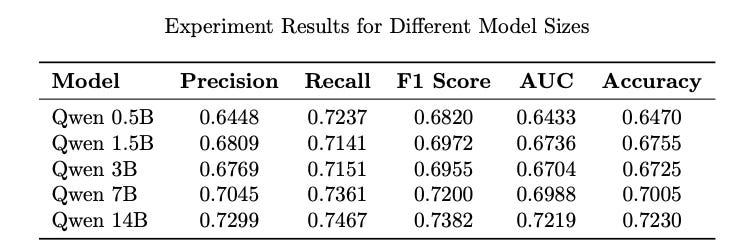
Performance gains in employing bigger models can be observed.
Interestingly, going from 1.5B to 3B model doesn’t seem to improve performance, in face it seems to deteriorates a bit. Not sure what’s going on there!
Data Efficiency
To study the data efficiency of larger models, an experiment I conducted is to train models for 200 steps (13200 ~ 16% examples) and compare their performance.
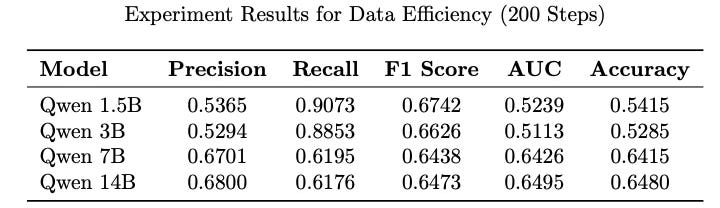
After 200 steps, smaller models are close to random predictions while larger models managed to learn quite a bit.
The phenomenon of diminishing returns is quite pronounced in going from 7B to 14B parameter model. The results are comparable to traditional recommendation models (e.g., SASRec) trained for multiple epochs.
Scaling: Add user attributes
Another scaling I tried is to incorporate more input features. The MovieLens dataset also contains demographic information on users. In particular, we have the genders, age groups, and occupations of the users. Using these attributes, I modified the input prompt as follows:
## Instruction:
Based on a user's profile and viewing history, predict whether the user will like the target movie or not. Only output the prediction as Yes or No.
## User Profile:
- Age: Younger than 18 years old
- Gender: Female
- Occupation: K-12 Student
## Viewing history:
- Liked "Girl, Interrupted (1999)"
- Disliked "Titanic (1997)"
...
- Liked "Star Wars: Episode IV - A New Hope (1977)"
## Target movie:
"Wallace & Gromit: The Best of Aardman Animation (1996)"
## Response: Results:
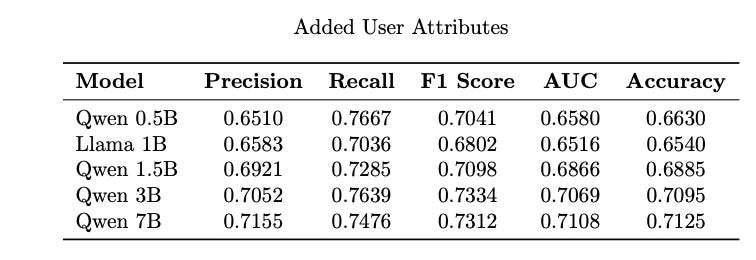
Models show consistent gains by incorporating user attributes, even the smaller models exhibit improved performance.
Cold-start
A point of adding user attributes is to be able to use the model in cold-start situations for user with limited to no past interaction history. To this end, let’s evaluate the performance of the models in cold-start setup.
Data: For every test example, I removed their past history, and used the prompt comprising of only the user attributes. The same model (i.e. trained on both user attributes as well as user histories) are used for the evaluation.
## Instruction:
Based on a user's profile and viewing history, predict whether the user will like the target movie or not. Only output the prediction as Yes or No.
## User Profile:
- Age: Between 18 and 24 years old
- Gender: Male
- Occupation: Self-Employed
## Viewing history:
## Target movie:
"Repo Man (1984)"Results: The following table shows performance of models in this cold-start set up.
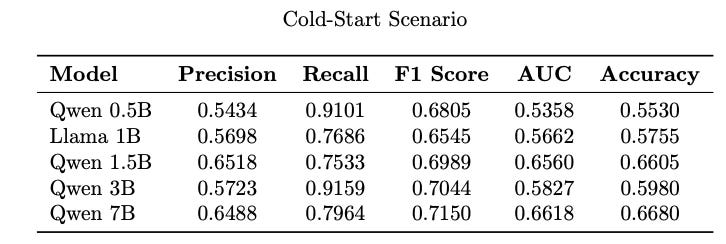
Models trained on user attributes in addition to user history show good gains in cold-start scenarios.
Here again we observe that Qwen 1.5B is quite robust model exhibiting better performance than 0.5B and 3B in cold-start scenarios.
Barring the 1.5B model, model size does seem to correlate to the ability of the model to learn better.
Movie Recommendation Model
We select the Qwen2.5 7B model fine-tuned on the instructions containing both past history and the user demographics as the proposed model for movie recommendation. Training with user attributes also improves the performance of the model in the case where no user attributes are available i.e., only past history as input.

This model is available on HuggingFace as januverma/Qwen7B_movierec from where it can be downloaded to be experimented with.
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "januverma/Qwen3B_movierec",
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model)Look at the Colab notebook on how to play with it. This is a fairly simple model that predicts Yes or No for a target movie. I’ll continue to improve both the performance and utility of this model.
Conclusion
This work extends our previous exploration of fine-tuning LLMs for movie recommendation in two significant ways:
Scaling Model Size: By experimenting on different models sizes (0.5B to 14B parameters), we observed measurable gains in precision, recall, AUC-ROC, and accuracy, albeit with diminishing returns as model size grew.
Incorporating User Attributes: Including user demographic features in prompts improved performance and addressed cold-start scenarios, especially for larger models that can effectively leverage the additional contextual cues.
Key Takeaways
Data Efficiency: Even with limited training examples, LLMs can outperform or match specialized recommendation models, thanks to their pre-trained linguistic and world knowledge.
Trade-offs: The improved performance from larger models comes at the cost of increased computational requirements. We must weigh these benefits against higher inference latency and resource usage.
Future Directions: Fine-grained personalization (e.g., combining textual movie descriptions or external knowledge graphs) could further enhance the model’s recommendation capabilities. Optimizing prompts also remain productive areas of research something I have not explored at all.
By continuing to develop these methods, we can refine and deploy more sophisticated, data-efficient, and highly personalized recommendation systems powered by state-of-the-art language models.
If you find this post useful, I would appreciate if you could cite this work as:
@misc{verma2025llm4recsysII,
title={Large Language Models for Recommender Systems II: Scaling},
author={Janu Verma},
year={2025},
url={\url{https://januverma.substack.com/p/large-language-models-for-recommender}},
note={Incomplete Distillation}
}