Large Language Models for Recommender Systems III - Synthetic Data
Does synthetic data help recommendation?

Introduction
Large Language Models (LLMs) have emerged as transformative tools in recommendation systems, challenging traditional methods like matrix factorization and collaborative filtering. Unlike these traditional approaches, which rely on implicit user-item interaction patterns, LLMs leverage their pre-trained linguistic capabilities to interpret nuanced contextual cues—such as movie plots, user reviews, or metadata—to infer preferences. For instance, an LLM might recognize that a user who enjoyed Inception and The Matrix is drawn to cerebral sci-fi, even if those films were never explicitly linked in training data. This ability to "read between the lines" enables LLMs to capture explanatory signals, offering not just predictions but potential rationales for recommendations.
Past Work
In prior research, I demonstrated that smaller LLMs (1B–7B parameters), when fine-tuned on minimal user interaction data (e.g., liked/disliked movie histories), could match or exceed the accuracy of conventional recommendation algorithms. By framing recommendations as a text-generation task—inputting user histories and outputting binary labels—these models leveraged their pre-trained knowledge of semantic relationships between films.
In another work, I experimented with enriching the training data by utilising user demographic attributes. This showed an improvement in the performance over only historical interactions in the input. This also resulted in gains in cold-start scenarios, especially larger models that can effectively leverage the additional contextual cues. Extending this line of thought, I started thinking about other ways to enrich the input data. This, coupled with other avenues to leverage LLMs for recommendation tasks, inspired my exploration of synthetic data as a means to enrich training signals, particularly for smaller LLMs with constrained parameter counts.
Synthetic Data
Synthetic data has emerged as a powerful tool to address data scarcity, augment training sets, and infuse richer context into models. This has paved the way for efficient and scalable supervised fine-tuning (SFT) for large language models (LLMs), particularly when adapting general-purpose models to specialized downstream tasks. By leveraging generative capabilities of frontier LLMs (e.g., GPT-4, Claude 3), practitioners can create tailored training datasets that address critical bottlenecks in real-world data availability, diversity, and explainability.
Task-Specialized Data Generation:
Frontier LLMs (e.g., GPT-4) generate labeled examples for niche domains (e.g., legal QA, medical text), bypassing costly human annotation. For instance, synthetic user query-response pairs fine-tune models for customer support or code debugging.Diversity Injection:
Synthetic data introduces edge cases (ambiguous instructions, multi-step reasoning) and stylistic variations, reducing overfitting to narrow real-world datasets. Models trained on procedurally generated arithmetic problems, for example, generalize better to unseen math competitions.Reasoning Integration:
Chain-of-thought (CoT) rationales, synthetically generated by advanced LLMs, train smaller models to decompose tasks (e.g., “Step 1: Identify intent → Step 2: Extract facts”). This improves explainability and accuracy in high-stakes domains like healthcare.Efficient Knowledge Distillation:
Synthetic input-output pairs from frontier models allow smaller LLMs to mimic advanced reasoning at lower cost. Parameter-efficient methods like LoRA enable fine-tuning on synthetic task data without forgetting pre-trained knowledge.
Current Work
In this work, the objective is to leverage synthetic data for the specific goal of improving recommendations. While prior efforts focused solely on like/dislike prediction from user histories, here we go one step further. By leveraging a frontier LLM (GPT-4o), I generate reasoning or explanation for a user’s like/dislike of a target movie based on their past interactions. This synthetic data is then used to fine-tune smaller LLMs to generate reasoning as well as the like/dislike label. By providing explanations in the training set, we hypothesize that smaller models can internalize patterns more effectively—learning not just the “what” of user preference, but a textual rationale that might further anchor the predicted label. This can be thought of as ‘distillation’ in an abuse of notation where we train smaller models on the outputs from a frontier model.
Generating Reasoning Data
I randomly sampled a set of 10K (out of 88K) training samples. Each example is of the form (past movies, target movie, label) where the label is the actual user response to the target movie. OpenAI API is then used to generate potential reasoning for the user’s response label based on the past movies. The reasoning is generated in a retrospective manner i.e. the model is provided with the label as asked to provide a reason for the label.
To create the synthetic data, we supplied GPT-4o with:
A user’s last 10 movies, marked liked or disliked.
A target movie and the label for it i.e. like or dislike.
The prompt for GPT-4o has the following system instructions:
You are a movie analysis assistant. You will be provided with data in the form of a triple containing:
1. **User’s Movie History:** A list of movies along with the user's responses (e.g., liked or disliked).
2. **Target Movie:** A specific movie from the user's history.
3. **User Response:** The user's reaction to the target movie (e.g., like or dislike).
Your task is to generate a clear, concise reasoning (like a chain-of-thought) for the user's response to the target movie. The reasoning should be based on the attributes of both the target movie and the user's movie history.
## Instructions
1. **Review the User’s Movie History:**
- Identify common themes, genres, eras, and stylistic elements among the movies.
- Note patterns in the user's responses that might indicate specific preferences or aversions.
2. **Analyze the Target Movie:**
- Consider the genre, themes, style, and other notable attributes of the target movie.
- Think about how these characteristics align with or differ from the elements present in the user's movie history.
3. **Generate the Reasoning:**
- Provide a brief reasoning that links the target movie’s features to the user’s response.
- Talk about the user response in future tense.
- Reasoning **should not** be more than 50 tokens.
## Input Format
- **User’s Movie History:** A list of movies with responses (e.g., liked/disliked).
- **Target Movie:** A movie from the user's history.
- **User Response:** "like" or "dislike".
## Your OutputThe model’s output was curated and filtered, ensuring coherence and correctness. We removed contradictory responses, random hallucinations, or irrelevant statements. The final curated dataset entries follow this structure:
{
"past_10_movies": [...],
"target_movie": "...",
"reasoning": "...",
"label": "Yes" or "No"
}Fine-Tuning on Synthetic Data
We then took a small-scale LLM Qwen2.5 1.5B model (similar to our earlier work) and fine-tuned it using this reasoning-augmented dataset. The prompts for training build on the past work and look like:
## Instruction:
Below is a user's history of likes and dislikes for movies, followed by a target movie. Predict whether the user will like the target movie or not. Think about how the characteristics of the target movie like genre, themes, style etc. align with or differ from the elements present in the user's movie history.
## User’s history:
- Disliked "Hoosiers (1986)"
- Liked "Schindler's List (1993)"
.....
- Liked "Godfather: Part II, The (1974)"
- Liked "Modern Times (1936)"
## Target movie:
"Blue Collar (1978)"
## Response:
The user will like "Blue Collar" due to their preference for character-driven narratives found in films like "Bound for Glory" and "Goodbye Girl, The," as well as the social realism and depth similar to "Schindler's List."
My final prediction is: $\boxed{Yes}$<|endoftext|>The training objective was twofold:
Generate a short textual explanation matching the “reasoning” field.
Output a binary label (“Yes” or “No”) reflecting the user’s likely preference.
We again used Low-Rank Adaptation (LoRA) to minimize the number of trainable parameters, keeping the process computationally manageable. The idea was that the textual explanations might serve as additional clues, helping the smaller models converge to robust patterns of user taste. Out of the 10K samples, 9K were used for training and 1K for validation. The model was trained for 3 epochs.
Label Prediction
The fine-tuned model was evaluated on a held-out real MovieLens test set (same as in the earlier studies), judging them solely on binary label accuracy (like/dislike). The results were encouraging:
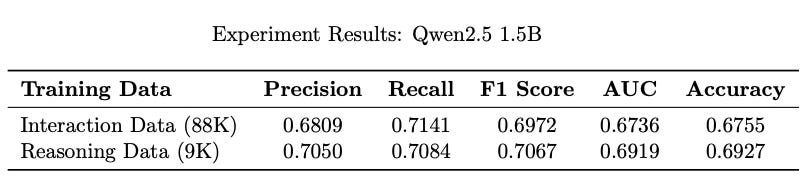
Also trained Qwen2.5 7B model
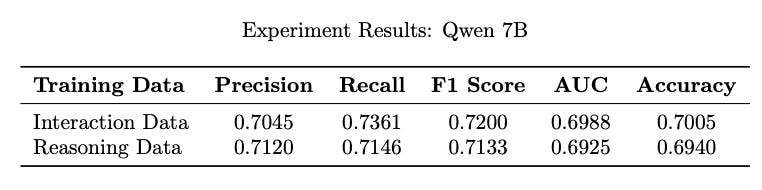
Comparable or Improved Performance: Models trained on reasoned synthetic data performed on par with, and sometimes slightly better than, those trained without explanations.
Data Efficiency: The presence of explanations helped the model reach a strong baseline in fewer samples than standard user-history-only training. The reasoning appended data is much smaller (~ 10%) than the whole engagement data.
Working with smaller dataset does require substantial hyper-parameter tuning for it to work best. I did not go deep into this rabbit hole, it could be an interesting exploration on its own. Though played with different values of learning rates.
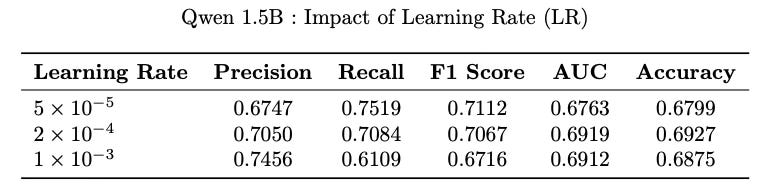
Model
The model is available on HuggingFace to try out as januverma/MovieRec-1.5B
## Load Model
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "januverma/MovieRec1.5B",
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model)
## Build Prompt
INSTRUCTION = (
"## Instruction: \nBelow is a user's history of likes and dislikes for movies, followed by a target movie."
" Predict whether the user will like the target movie or not."
" Think about how the characteristics of the target movie like genre, themes, style etc. align with or differ from the elements present in the user's movie history.\n\n"
"## User’s history:\n"
)
def create_prompt(prompt, past_movies, candidate):
for movie in past_movies:
title, genre, rating = movie.split(":::")
if int(rating) > 3.0:
prompt += f'- Liked "{title}"\n'
else:
prompt += f'- Disliked "{title}"\n'
target_movie_title, target_movie_genre = candidate.split(":::")
prompt += f'\n## Target movie:\n"{target_movie_title}"\n'
prompt += f'\n## Response:\n'
return prompt
prompt = create_prompt(INSTRUCTION, past_movies, candidate)
## Run Model
inputs = tokenizer([prompt], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 128, use_cache = True)
print(tokenizer.batch_decode(outputs)[0])Further
Explainability Potential: Though untested in a user-facing scenario, the generated “reasoning” could offer a path toward more transparent recommendations.
Importance of Quality Control: Any spurious or contradictory synthetic text could hinder learning. Proper curation was key.
Promising Direction: These findings hint that injecting textual rationales is a valuable method for boosting small LLM performance in recommendation tasks.
Conclusion
This work demonstrates a new avenue for improving movie recommendation models: using a frontier LLM to generate synthetic reasoning and integrating that reasoning into training data. The results show that smaller LLMs can benefit significantly from these curated explanations, yielding high accuracy in predicting whether users will like or dislike a movie.
Moving forward, incorporating real user feedback or detailed metadata into these synthetic rationales could further enhance both performance and explainability. The approach also underscores the broader value of synthetic data generation—when guided by a powerful model and carefully curated—for boosting downstream tasks in recommender systems.
Citation
If you find this post useful, I would appreciate if you could cite this work as:
@misc{verma2025llm4recsysIII,
title={Large Language Models for Recommender Systems III: Synthetic Data},
author={Janu Verma},
year={2025},
url={\url{https://januverma.substack.com/p/large-language-models-for-recommender-807}},
note={Incomplete Distillation}
}