Large Language Models for Recommender Systems
Can LLMs reason over user behaviour data to decipher preferences?

Introduction
Over the years, recommendation systems (RecSys) have evolved significantly, progressively through a variety of paradigms, notably:
Classical Collaborative Filtering: Simple memory-based approaches that leveraged user–item co-occurrence.
Matrix Factorization: Methods such as Singular Value Decomposition (SVD) allowed modeling of users and items in a shared latent space, improving scalability and generalization.
Deep Neural Recommenders: With the advent of deep learning, architectures like multi-layer perceptrons, convolutional neural networks, and recurrent neural networks were introduced to capture more complex interactions.
Transformers for Recommendation: Recently, the self-attention mechanism of Transformers has shown promise for modeling long-range dependencies and sequential patterns in user behavior.
Large Language Models (LLMs) have demonstrated remarkable capabilities in generalizing to new tasks with minimal task-specific data, often excelling in zero-shot or few-shot scenarios. A curious question is how these models—designed primarily for language tasks— fare in recommendation tasks. The ability of LLMs to fully understand user preferences from their past behaviour is still an evolving area of research with many unanswered questions. This is what I intend to explore in this project. This is first report of the project where we focus on the recommendation task of whether the user will like or dislike a candidate item.
Why might Large Language Models (LLMs) be effective at recommendation tasks?
World Knowledge: LLMs have a vast parameter space (billions of parameters) and are trained on diverse text from the internet. This pre-training instills extensive general world knowledge in LLMs i.e., a sense of how language—and by extension, certain item attributes and user preferences—might relate. An LLM could theoretically capture subtler interactions (e.g., “users who love dark comedies also enjoy certain types of thrillers”) simply by virtue of having read vast amounts of related text during pre-training.
General Reasoning: LLMs exhibit powerful pattern recognition abilities, which extend beyond simple text completion. The reasoning capabilities of LLMs provide a strong indication of their potential for recommendation tasks. By leveraging their ability to understand complex relationships, infer user preferences, and analyze contextual patterns, LLMs can go beyond simple item-to-item associations. Their capacity to draw insights from past interactions, recognize underlying themes, and generalize across domains suggests that they can offer personalized recommendations with a deeper contextual awareness. This reasoning ability allows LLMs to make nuanced suggestions by considering factors such as sentiment, evolving preferences, and broader trends, positioning them as powerful tools for recommendation systems that require adaptive and dynamic decision-making.
Overall, the world knowledge, general reasoning and pattern-finding strengths of LLMs make them a promising new tool in the recommender’s arsenal. They can potentially go beyond standard collaborative filtering by leveraging extensive pre-training on real-world text, enabling them to capture and reason about subtle thematic connections, user preferences, and domain knowledge in a natural and flexible way.
Current Work
In this work, I conduct various experiments to explore the prowess of LLMs for recommendation tasks. For building a proof of concept, I use small language model (SLM) - Llama 3.2 1B - and minimal featurization of the user histories.
Smaller models allow rapid prototyping and experimentation with different settings (e.g., zero-shot, few-shot, fine-tuning) with shorter training times. Larger models require significant compute resources, leading to higher financial costs.
Given the relatively simple nature of the input sequences (last 10 movies), the 1B model is adequately capable of capturing sufficient context. A assertion worth testing.
Using the 1B model helps establish an initial baseline; larger models can be explored later based on empirical findings.
Smaller models are easier to deploy in real-world applications.
This report is an investigation on the feasibility of using Llama 3.2 1B for the task of movie recommendation. Specifically, the aim is to predict whether a user will like a candidate movie based on their past engaged movies. Movies are chosen as it is expected that the LLM would have developed general knowledge about movies during their pre-training.
Set up:
Data: We utilize the MovieLens 1M dataset, a well-known benchmark for movie recommendation systems. The dataset contains 1,000,209 ratings from 6,040 users on 3,952 movies, spanning across 18 genres. Each rating is provided on a scale from 1 to 5, with timestamps, enabling temporal sequence modeling.
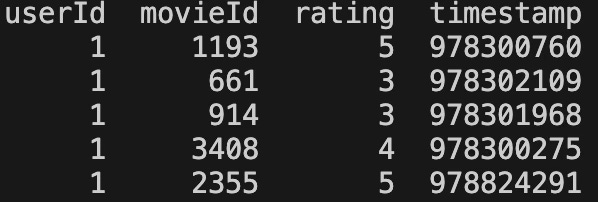
Preprocessing: We convert the explicit ratings into an implicit feedback format to formulate the problem as binary classification:
Ratings ≥ 4 → Positive interaction (Like)
Ratings < 4 → Negative interaction (Dislike)
Train/Val Split: We take the first 90% ratings of every user as the training set and the remaining 10% as the test set. Due to the high computation cost of zero-shot and few-shot experiments based on LLMs, we randomly sample 2000 examples from the test set as a smaller test set. For all the experiments, we reported results are on the sampled test set.
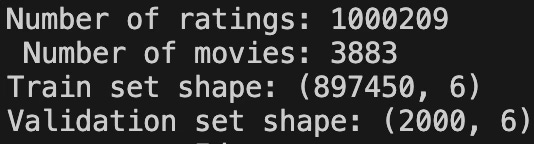
Problem Formulation: We frame the problem as a binary classification task, where the objective is to predict whether a user will like a given movie based on their recent viewing history.
Input: The input to the models includes:
History of watched movies: Represented by their IDs.
Candidate Movie Id
Optional additional features:
Titles of movies
Genres of movies
Ratings given to the watched movies
Temporal information (timestamps)
Output: The output of the model are the predicted labels.
1 (Positive): The user liked the candidate movie.
0 (Negative): The user did not like the candidate movie.
Baseline Models
Singular Value Decomposition (SVD): SVD is a matrix factorization technique commonly used in collaborative filtering. It decomposes the user-item interaction matrix into latent factors representing user preferences and movie features. The model aims to reconstruct user ratings by optimizing the factorized matrices.
Captures latent relationships between users and items.
Works well with sparse data.
Optimized using Stochastic Gradient Descent (SGD) with RMSE loss.
We view the training data as a sparse matrix and use it to learn SVD which is the used to estimate the ratings of the (user, movie) pairs in the test data. The predicted ratings are converted into binary labels.
MF methods model static user-movie relationships and are oblivious to the sequential structure in user watch history. To have a better baseline for LLM-based approaches, we also train a sequential recommendation model, called Self-Attentive Sequential Recommendation (SASRec).
SASRec: SASRec is a deep learning-based sequential recommendation model that leverages the self-attention mechanism to capture sequential patterns in user behavior. Unlike traditional models, it focuses on learning long-term dependencies within user sequences.
Utilizes self-attention layers to model sequential dependencies.
Handles dynamic sequence lengths effectively.
Suitable for learning personalized user preferences over time.
Tunable hyperparameters such as attention heads, hidden dimensions, and number of blocks.
To model user behaviour, we consider the last 10 watched movies as sequential input for predicting the like/dislike of a candidate movie. For every training instance, we extract the user’s last 10 watched movies prior to the candidate movie and sort them by timestamps to produce an input context sequence. The task is then to predict whether the user will like the target movie given the last 10 watched movies. The movies in the input sequence and the candidate are represented by their Ids.
Input Seq: [3186, 1721, 1270, 1022, 2340, 1836, 3408, 1207, 2804, 260]
Candidate Movie: 720
Label: 0Set up for training SASRec. We use 2 attention heads, and 2 transformer blocks, with hidden dimension 64. We do not do any hyperparameter tuning.
Evaluation Metrics
We use the following metrics to evaluate the models:
Precision: proportion of predicted “likes” that are actually correct
Recall: proportion of actual “likes” that were correctly identified
ROC-AUC: measures the model’s ability to distinguish between positive and negative classes across different thresholds.
Accuracy: measures the overall proportion of correct predictions across both positive and negative classes.
Baseline Experiments:
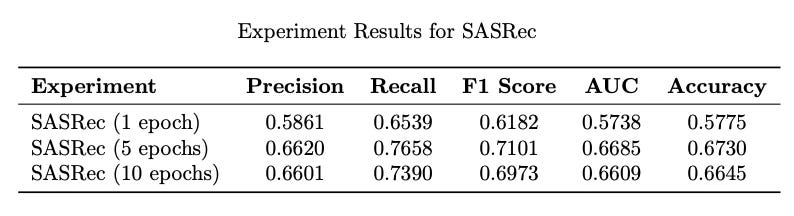

SVD achieved high precision but suffered from low recall, indicating difficulty in identifying relevant movies.
For SASRec, the performance improved with longer training, achieving competitive results in recall and F1.
LLM Experiments:
Since LLMs use textual input, we use the titles of the movies.
0-shot Learning:
We will use pre-trained Llama 3.2 1B Instruct model which is trained and tuned for instruction following. Let’s frame the recommendation task as an instruction prompt.
Prompt:
## Instruction:
Below is a user's history of likes and dislikes for movies, followed by a target movie. Predict whether the user will like the target movie or not. Only output the prediction as Yes or No.
## User’s history:
- Liked "Girl, Interrupted (1999)"
- Disliked "Titanic (1997)"
...
- Liked "Star Wars: Episode IV - A New Hope (1977)"
## Target movie:
"Wallace & Gromit: The Best of Aardman Animation (1996)"
## Response:Few-shot Learning:
We use 3 examples to appeal to the in-context learning of the model. Every input prompt is pre-pended with the following:
## Instruction:
Below is a user's history of likes and dislikes for movies, followed by a target movie. Predict whether the user will like the target movie or not. Only output the prediction as Yes or No.
## Example 1
### User's rating history
- Liked "Girl, Interrupted (1999)"
....
- Disliked "Christmas Story, A (1983)"
- Disliked "Star Wars: Episode IV - A New Hope (1977)"
### Target movie:
"Wallace & Gromit: The Best of Aardman Animation (1996)"
## Response:
No
## Example 2
### User's rating history
- Liked "One Flew Over the Cuckoo's Nest (1975)"
- Liked "Wizard of Oz, The (1939)"
....
- Disliked "Driving Miss Daisy (1989)"
### Target movie:
"Mary Poppins (1964)"
## Response:
Yes
## Example 3
### User's rating history
- Liked "Bambi (1942)"
- Liked "Apollo 13 (1995)"
....
- Disliked "James and the Giant Peach (1996)"
- Liked "Ferris Bueller's Day Off (1986)"
### Target movie:
"Secret Garden, The (1993)"
## Response:
Yes
## Now, do the same for the following user
## User’s history:Results:
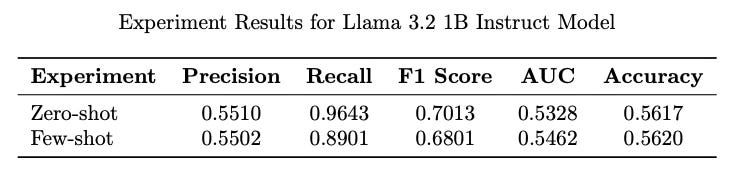
Zero-shot and few-shot models achieved high recall but exhibited lower precision, indicating a tendency to over-predict positive cases. This is opposite to the SVD model where precision was high but recall quite low.
AUC scores were relatively low, close to random, highlighting limited discrimination ability.
Supervised Fine Tuning (SFT):
This highlights what we suspect. LLMs aren’t magic out of the box. Pre-trained models don’t understand your dataset or task until they’ve been fine-tuned. Next set of experiments aim to bridge that gap by teaching pre-trained models how to predict movie preferences from user history via supervised fine-tuning (SFT). By treating recommendation as an instruction-following task, LLMs can learn preferences and patterns in user histories.
Instruction Data: We construct an instruction-like dataset from the MovieLens training split, converting each user–movie interaction into a prompt-response pair. The prompt contains the user’s last 10 liked/disliked movies (titles) plus the target movie title. The response is “Yes” or “No.”
Setup: We used parameter-efficient fine-tuning method LoRA on instruction data created from the training data and evaluated on the test set. Batch size 64, AdamW optimiser with LR 5e-5 and weight decay 0.01. As convention, we used a learning rate scheduler (linear) with 20 warm up steps. We use 4-bit quantization and the Unsloth library for faster training on a single GPU. The LoRA rank is chosen to be 16.
Results: The LoRA model trained on instruction data shows good performance.
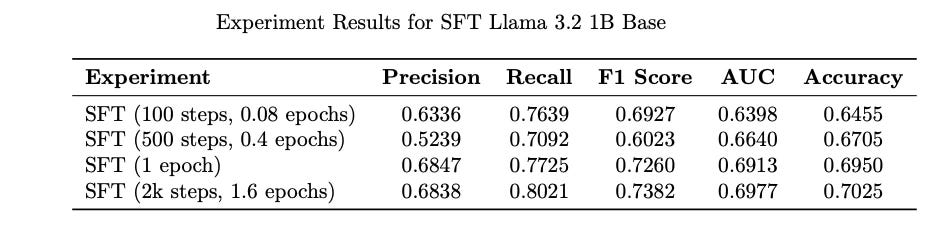
Data Efficiency of LLMs: Observe that after training only 100 steps (6400 examples), the performance of fine-tuned model is already better than SVD and comparable to SASRec. Since LLMs acquire extensive world knowledge during pre-training, unlike traditional recommender models that are trained from scratch, LLMs are expected to demonstrate superior data efficiency. It takes LLM fine-tuning 500 steps (32,000 examples) to surpass SASRec model trained for 10-epoch (~ 900,000 instances). This highlights why LLMs would be desirable for recommendation tasks.
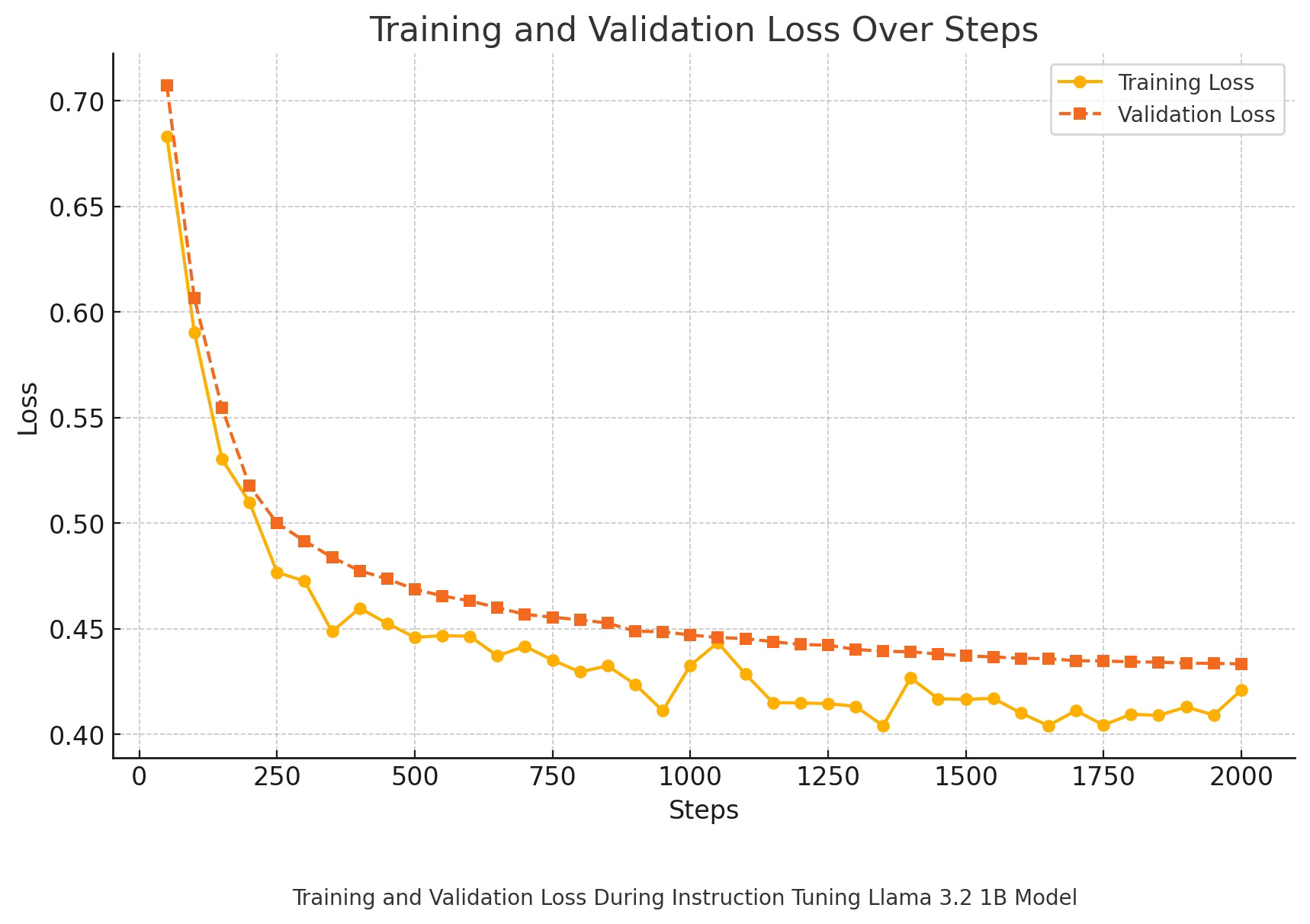
Overall, the results of the experiments look like:
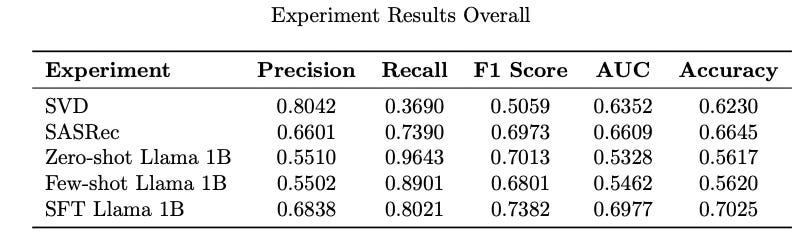
We observe that supervised fine-tuning with LoRA showed:
Significant improvement in precision (addressing the over-prediction of positives).
Competitive or superior performance compared to SVD and SASRec on metrics such as recall and AUC.
Better generalization on the 2,000-sample test set than the zero/few-shot approach.
Additional Metadata: In another set of experiments, I tried adding additional data about movies in the prompts.
Genres: Genres of the past movies as well as the candidate movie are provided in the prompt.
<Liked “Princess Bride, The (1987)” of genre “Action|Adventure|Comedy”>
Explicit Ratings: The explicit numeric rating that the user gave to the past movies are added in the prompt.
<"Man Who Knew Too Much, The (1956)" is rated 5.0>
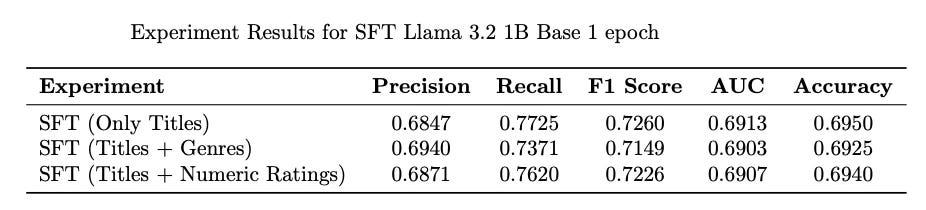
This improves precision a bit. I would not have expected genres to make much difference as LLMs should already possess this knowledge via their pre-training. I do believe ratings can be handled better, in fact initial experiments prove (will be covered in subsequent post).
Related Work:
LLMs in RecSys has drawn attention recently in academic circles. Some work closer to this discussion here are:
Large Language Models are Zero-Shot Rankers for Recommender Systems by Yupeng Hou et al. In this work, they explore the capabilities of the state-of-the-art LLMs like GPT-4 as zero-shot rankers. This is different from our work in that they focus on the ranking task and only operate in zero-shot setting, they do not consider fine-tuning.
TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation by Keqin Bao et al. In this work, the authors fine-tune LLMs for a recommendation task which is similar to ours. However, they first tune base model to follow instructions by doing an Alpaca-style fine-tuning, and then further fine-tune on recommendation task. In contrast, the current work fine-tunes the base model directly on engagement data.
Do LLMs Understand User Preferences? Evaluating LLMs On User Rating
Prediction by Wang-Cheng Kang et al studies the potential of LLMs of different sizes (250M - 540B) in zero-shot and fine-tune settings. This is different from our work as they attempt rating prediction task. Further, they fine-tune Flan-T5 11B model by adding a regression/classification head rather than text generation setup adapted in our work.
Conclusion:
In this report, we have outlined the setup and baseline models for our investigation into using LLMs for movie recommendation.
Key Findings:
Zero-shot/few-shot LLMs provide a reasonable starting point but struggle with precision and overall discriminative performance.
Fine-tuned LLMs via LoRA adaptation show significant improvement, matching or exceeding traditional recommendation models.
SVD and SASRec models serve as strong baselines, with SVD excelling in precision and SASRec providing a good trade-off between recall and precision.
Incorporating additional user-item features (e.g., ratings, genres) enhances fine-tuned LLM performance.
Future Work:
This work sets the foundation for the experimental phase, where we aim to validate the effectiveness of LLMs in personalized recommendation tasks. In future, I will share a report on further explorations. Current work includes:
Scaling Up: Using larger LLMs and assess improvements in predictive accuracy.
Rich User/Item Features: Incorporate user profiles, genres, ratings, or textual metadata (e.g., plot summaries, reviews).
Hyperparameter Tuning: Systematically optimize LoRA rank, learning rate, and prompt-engineering strategies.
Advanced Tasks: Extend beyond binary classification to tasks like:
Top-N Ranking: Which movies are most relevant for the user?
Rating Prediction: Estimate the user’s star rating.
Personalized Summaries: Generate textual recommendations explaining why a user might enjoy a particular movie.
By progressively exploring these facets, we can build a clearer picture of how LLMs can transform the landscape of recommendation systems, potentially unlocking a new generation of highly personalized and context-aware recommenders.
If you find this post useful, I would appreciate if you could cite this work as:
@misc{verma2025llm4recsys,
title={Large Language Models for Recommender Systems},
author={Janu Verma},
year={2025},
url={\url{https://januverma.substack.com/p/large-language-models-for-recommender}},
note={Incomplete Distillation}
}
Nice writeup, thanks! Is your code available somewhere to experiment and build on top of?
i don't think SFT is a viable approach for personalized recommendations. Are you going to train 1 LoRA adapter for every user?