
Introduction
Recommendation systems are central to modern digital platforms, from e-commerce and streaming services to news aggregation and social media. At their best, they anticipate user needs, surface relevant content, and personalize the user experience at scale. Traditionally, these systems have relied on opaque identifiers, arbitrary IDs assigned to users and items, and learned dense vector embeddings through collaborative signals. While powerful, this approach suffers from key limitations: cold-start issues, poor generalization, and a reliance on interaction history rather than intrinsic content.
Semantic IDs offer a compelling alternative. By replacing meaningless identifiers with structured, discrete representations derived from the actual content, such as text, metadata, or imagery, Semantic IDs bring semantics into the very backbone of recommendation. Techniques like Residual Quantization and RQ-VAE allow us to map high-dimensional embeddings to compact code sequences that reflect meaningful attributes: genre, brand, author, visual style, or topical theme. These IDs are compositional, interpretable, and transferable across domains. Instead of learning to associate item_98124 with a user, the system learns that they like “sci-fi thrillers directed by Christopher Nolan” - and can act accordingly, even for new or long-tail items.
In a previous post, I explored the foundational ideas behind Semantic IDs and walked through the technical machinery that makes them possible: vector quantization, residual decomposition, and sequence modeling of discrete codes. That deep dive laid the groundwork. This post picks up from there and turns concept into execution.
Here, I train semantic IDs from real product data and integrate them directly into a recommendation pipeline. I experiment with learning semantic IDs using a simple residual quantization (RQ) method, and use them in recommendation tasks like rating prediction, candidate retrieval, next item prediction etc. I also conduct ablation studies analyzing semantic IDs.
The codes used in this work are available at: semantic-ids-for-recommendation-systems
Data
The data for this work comes from Amazon product reviews, particularly the Beauty dataset for this experiment. Rather than processing raw data, we use the processed provided with P5 recommendation model. The data contains user interaction sequences with beauty products along with rich product metadata. The dataset includes 12,101 unique items with corresponding product information such as titles, brand names, category hierarchies, sales rankings, and detailed descriptions extracted from the product metadata. User-item interactions are mapped through a standardized ID system, which converts Amazon Standard Identification Numbers (ASINs) to sequential item IDs. This dataset is well-suited for evaluating content-based semantic representations due to its diverse product categories within the beauty domain and the availability of comprehensive textual metadata for each item, enabling meaningful content-based semantic ID generation through our proposed residual vector quantization approach.
Semantic IDs Generation
The semantic IDs are learned using Residual Quantization which is a powerful and highly scalable method for generating semantic IDs. RQ-KMeans is a memory-efficient variant of the k-means clustering algorithm. It uses the principles of residual quantization to represent a very large number of cluster centroids without having to store each one explicitly. At a high level, it works by repeatedly clustering the current residual (what’s left after previous quantizations), so that each embedding is ultimately represented by a small sequence of cluster indices rather than the full original vector.
For each item, textual metadata including title, brand, product categories, sales rank, and description is extracted. These heterogeneous features are concatenated into a structured text representation following the format:
"Title: [product title] | Brand: [brand name] | Category: [category path] | Description: [product description]".
This standardized format ensures consistent feature representation across all items in the dataset.
The textual representations are encoded using a pre-trained sentence transformer model (all-MiniLM-L6-v2) to obtain 384-dimensional dense embeddings. The sentence transformer captures semantic relationships between items based on their content features, providing a foundation for the subsequent quantization process.
A multi-level residual quantization scheme is employed to compress the embeddings into discrete semantic codes. Using 3 quantization levels with 256 clusters per level, we train K-means clustering models sequentially:
Level 1 clusters the original embeddings, capturing the primary semantic categories.
Level 2 clusters the residuals remaining after subtracting the Level 1 cluster centers, refining the semantic distinctions.
Level 3 further clusters the residuals from the first two levels, capturing fine-grained semantic differences.
At each level L, compute residuals by subtracting the quantized representations from previous levels, then apply K-means clustering to these residuals. This hierarchical approach allows the model to capture semantic relationships at multiple granularities.
For each item, its semantic ID is computed by finding the nearest cluster center at each level. This process assigns each item a 3-dimensional code where each dimension ranges from 0 to 255, representing the cluster assignment at each quantization level. The resulting semantic ID format is (c1, c2, c3) where each code indicates the cluster assignment at that level.
To ensure unique item identifiers, we need to eliminate cases where multiple items share identical 3-level semantic IDs. For items with colliding semantic IDs, a standard practice is to append a disambiguation suffix, creating 4-dimensional semantic IDs in the format (c1, c2, c3, <suffix>). Items without collisions receive a suffix of 0, while colliding items receive incremental suffixes (1, 2, 3, etc.).
Admittedly, this is a quite basic method for semantic Ids and there are more sophisticated methods that yield much more expressive and faithful semantic Ids. I chose RQ-KMeans for the ease of exposition and quicker experimentation. Further, most academic works use 768-dimensional sentence embeddings as opposed to 384 that is used here, again for simplicity.
Analysis
To validate the quality and characteristics of our generated semantic IDs, I performed comprehensive analysis across multiple dimensions including distribution patterns, collision resolution effectiveness, and semantic similarity preservation.
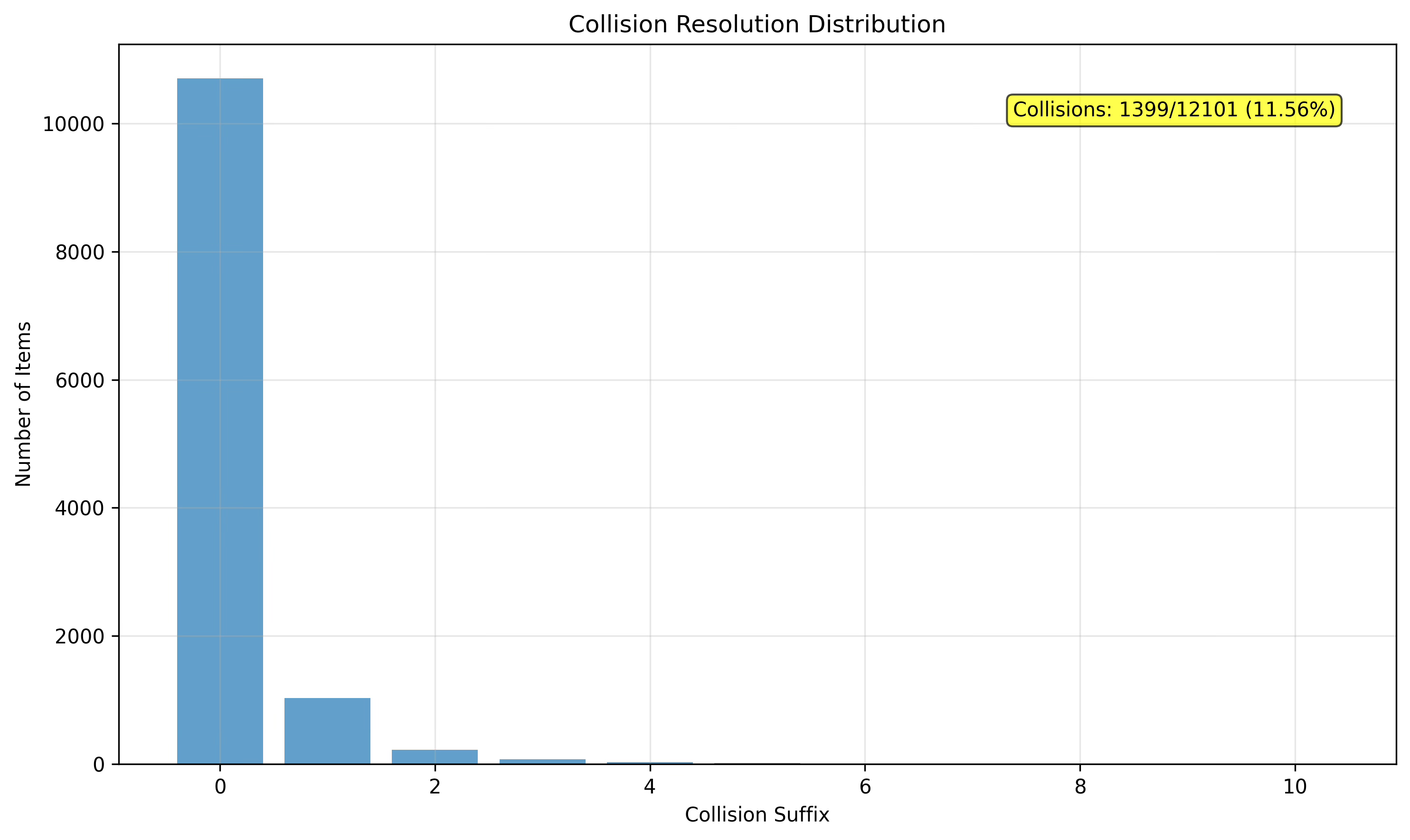
Distribution Analysis: First, I analyzed the distribution of codes across all quantization levels to assess the balance and utilization of the semantic space. The analysis revealed that all three quantization levels achieved full utilization of the 256-code space, with Level 1 showing relatively balanced distribution (most frequent code assigned to 191 items, least frequent to only 8 items). Level 2 demonstrated higher variability with the most common code appearing 325 times while some codes were assigned to only a single item. Level 3 showed the highest concentration, with the most frequent code (209) assigned to 532 items, indicating successful capture of fine-grained semantic distinctions. The collision suffix (Level 4) revealed that 10,702 items (88.4%) required no disambiguation, while the remaining items needed suffixes ranging from 1 to 10.
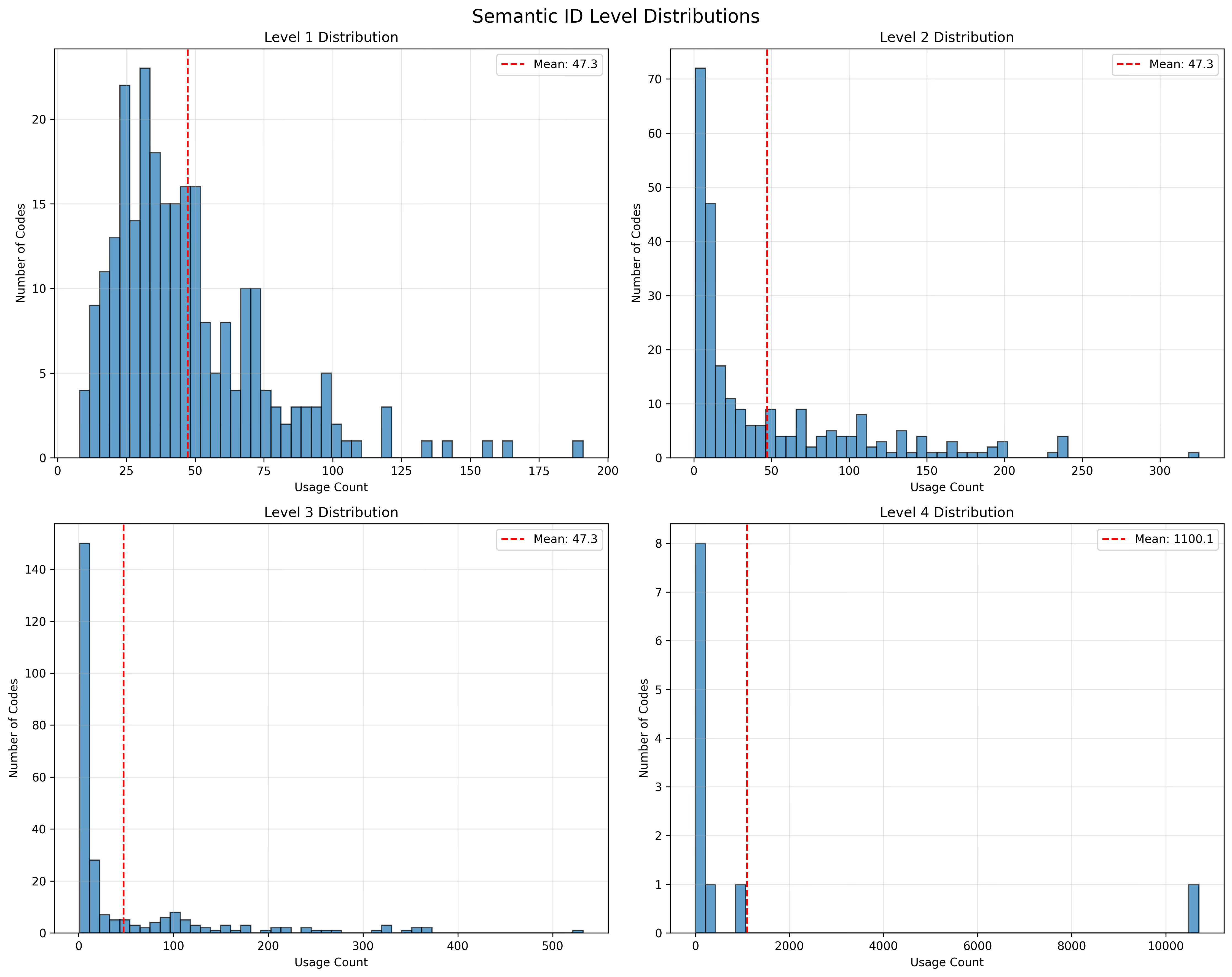
Collision Detection and Resolution Assessment: Our collision analysis identified 1,033 unique 3-level semantic IDs that experienced collisions, affecting 2,432 items total (20.1% of the dataset). The collision pattern analysis showed that most conflicts involved pairs of items (810 cases), with fewer cases requiring disambiguation of larger groups. The largest collision involved 11 items sharing the same semantic ID (28, 226, 207), while the majority of collisions (810 out of 1,033) involved exactly 2 items. This collision rate indicates that our 3-level quantization captures meaningful semantic distinctions while the suffix mechanism successfully resolves all conflicts.
Semantic Similarity: Using pairwise Hamming distance analysis on 1,000 sampled items (499,500 pairs), it seems that semantic IDs effectively preserve content-based relationships. The mean Hamming distance was 2.96 with a standard deviation of 0.20, indicating that most item pairs differ across nearly all three quantization levels. The distance distribution showed that 96.6% of pairs had maximum distance (3), 3.2% differed by 2 levels, and only 0.2% were highly similar (distance 0-1). This distribution suggests that our hierarchical quantization successfully spreads items across the semantic space while maintaining meaningful similarity relationships for closely related products.
This lends support to the notion that residual vector quantization successfully generates interpretable, collision-free semantic identifiers while preserving content-based item relationships across the 12,101-item beauty product dataset.
Semantic ID Matrix Factorization (SIMF)
To study the efficacy of the semantic Ids for recommendation systems, let’s start with one of the simplest recommendation architectures i.e. matrix factorization (MF) for collaborative filtering. The standard ID-based matrix factorization model decomposes the user-item rating matrix into low-rank user and item factor matrices, predicting ratings as:
where mu is the global mean rating, b terms are user and item bias terms.
The model parameters are optimized using stochastic gradient descent with L2 regularization to minimize the squared prediction error.
We adapt the standard MF to use semantic Ids and propose Semantic Matrix Factorization (SIMF) that incorporates content-based semantic representations. SIMF replaces the learned item embeddings with semantic embeddings derived from the hierarchical semantic IDs. Instead of learning individual item representations from scratch, SIMF constructs item embeddings by combining learned representations at each quantization level.
For each semantic level l, we learn an embedding table and a bias vector :
The item representation is then formed as a weighted composition of its codes:
where w_l are level weights that reflect the global importance of each semantic level. To ensure positivity and normalization, we parameterize weights via logits α ∈ R^L and apply a softmax:
This construction removes item-specific parameters. Any new item with known semantic codes can be represented on the fly.
Both models use identical hyperparameters for fair comparison: 32 latent factors, trained using stochastic mini-batch gradient descent (Adam optimizer) with learning rate 5e-3 and L2 regularization of 1e-4. Global mean is initialized to the training-set average rating. Predictions are not bounded during training, but at evaluation are clamped to the rating range [1, 5]. The key difference lies in the parameter update process. While standard MF learns both user and item embeddings, SIMF learns user factors and semantic codebook embeddings.
Performance is reported both as rating regression (RMSE, MAE) and as a binary classification task by thresholding ratings at 4.0 (positive vs. negative). Classification metrics include ROC-AUC, PR-AUC, Precision, Recall, F1, and Accuracy. We further analyze:
User and item frequency slices: head/mid/tail groups based on training interaction counts (20th/80th percentiles).
Cold-start performance: splitting test items into warm (seen in training) and cold (unseen in training).
Results
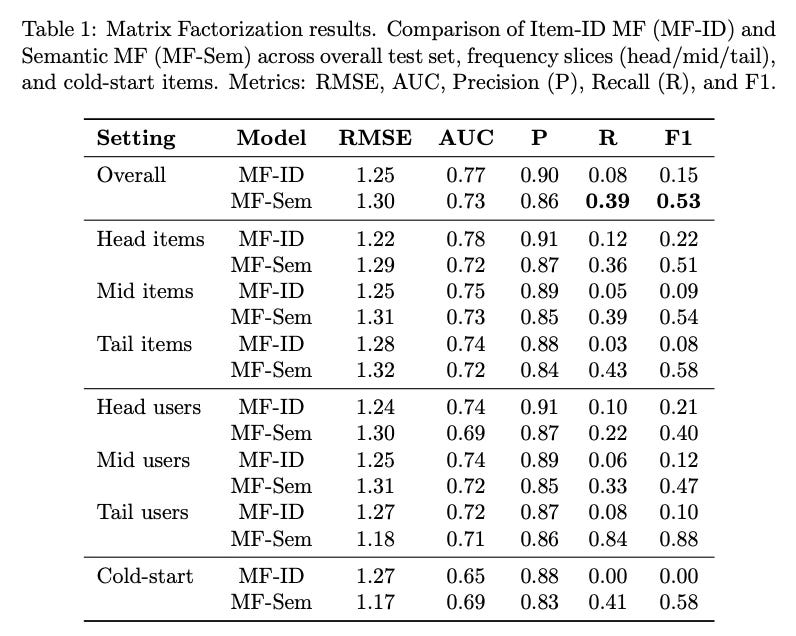
Overall, MF-ID achieves lower regression error (RMSE 1.25 vs. 1.30) and higher AUC (0.77 vs. 0.73), but suffers from extremely low recall (0.08) and thus very low F1 (0.15). MF-Sem, by contrast, improves recall substantially (0.39) and achieves a much higher F1 (0.53) and accuracy (0.60), albeit with slightly worse RMSE.
Slice analysis highlights the generalization advantage of semantic IDs. MF-ID performs competitively on head items and users but collapses on mid and tail groups, where its recall remains below 0.1. MF-Sem generalizes across all slices, achieving recall above 0.35 for mid and tail items and over 0.8 for tail users, leading to F1 scores above 0.5.
The starkest difference emerges in cold-start evaluation: MF-ID completely fails on unseen items (F1=0.0, AUC=0.65), whereas MF-Sem maintains robust performance (F1=0.58, AUC=0.69). These results confirm that semantic identifiers enable MF models to represent unseen items and improve coverage for sparse users, though at the cost of slight degradation on regression accuracy.
These experiments show the value of semantic IDs: they provide inductive bias and cold-start capability. However, MF is a very limited architecture compared to the models typically used in modern recommendation.
Practical Recommender Models
A fundamental challenge in evaluating semantic ID approaches for recommendation systems is the lack of fair comparison baselines. Traditional evaluations often compare semantic methods against collaborative filtering baselines that use only user-item interaction data, while semantic approaches leverage rich metadata (titles, descriptions, categories). This creates an unfair advantage for semantic methods due to information asymmetry rather than representational superiority.
A fair evaluation would ask the question: When both approaches have access to identical information content, do compressed semantic representations outperform explicit metadata features in deep learning recommendation models?
To explore this research question, we set up experiments where we provide the baseline the item features that were used to learn semantic Ids.
Experimental Design
Our methodology implements information equivalence by ensuring both baseline and semantic approaches process identical metadata content:
Baseline Model: User ID + Item ID + Explicit metadata features (title, description, brand, category, sales rank)
Semantic Model: User ID + 4-level semantic IDs (hierarchically encoding the same metadata)
This design isolates the impact of representation choice (explicit vs. compressed) while controlling for information content.
Data
To simulate realistic recommendation scenarios, we use chronological splitting:
Training Set: First 80% of interactions chronologically.
Validation Set: Next 10% for hyperparameter tuning and early stopping.
Test Set: Final 10% for final evaluation.
This ensures models are evaluated on future interactions, preventing temporal data leakage. We convert the recommendation task to binary classification following established practices:
Positive Label (1): Ratings ≥ 4.0 (user satisfaction)
Negative Label (0): Ratings < 4.0 (user dissatisfaction)
This formulation enables Click-Through Rate (CTR) prediction, a standard industry application.
Models
To effectively make use of the metadata and the model interactions between features, we use practical recommendation systems based on neural architectures for this experiment. In particular, we use:
Wide and Deep: WDL combines wide linear component for memorization and a deep multi-layer perceptron (MLP) for generalization. The deep input is the concatenation of all field embeddings (user, item/semantic, brand, category, text, salesRank). The wide input is a hashed cross of user and item (or user and semantic codes). The final prediction is
\(\hat{y} = \sigma \big( f_{\text{MLP}}([e_1;\ldots;e_F]) + w^\top \phi(u,i) \big)\)where
fis a two-layer MLP,phiis the hashed cross, andsigmais the sigmoid.DeepFM: DeepFM unifies a factorization machine (FM) component with a deep neural network. All features share embedding vectors that feed both:
\(\hat{y} = \sigma\!\Big( w^\top x + \tfrac{1}{2}\big[(\sum_i e_i)^2 - \sum_i e_i^2\big]\mathbf{1} + f_{\text{MLP}}([e_1;\ldots;e_F]) \Big)\)where the first two terms correspond to FM first- and second-order feature interactions, and
fis the deep component. Baseline fields include user, item, brand, category, text, and salesRank; semantic variants include user and semantic codes only.Deep Learning Recommendation Model (DLRM): DLRM models categorical and dense features separately, then combines them through explicit pairwise interactions. Categorical features are embedded, and dense features (e.g., salesRank) are processed by a bottom MLP. An interaction layer computes all pairwise dot products among embeddings (and optionally with the dense vector).
The result is concatenated with the dense vector and passed through a top MLP:
\(\hat{y} = \sigma \big( f_{\text{top}}( \text{interact}(E_1,\dots,E_C, D) \,\Vert\, D ) \big)\)Baseline models use user, item, brand, category, and text as categorical inputs, with salesRank as the dense input. Semantic models replace item+metadata with four semantic levels.
All models are trained with binary cross-entropy loss on explicit labels, using the Adam optimizer with learning rate 1e-3 and batch size 1024. Embedding dimension is set to 16, MLP hidden layers are (128, 64) with ReLU activations and dropout 0.1. Training is run for 3--5 epochs, with early selection based on validation ROC-AUC.
Results
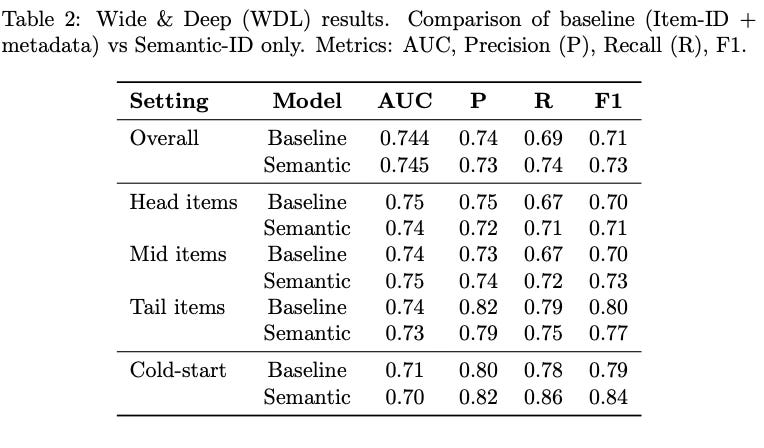
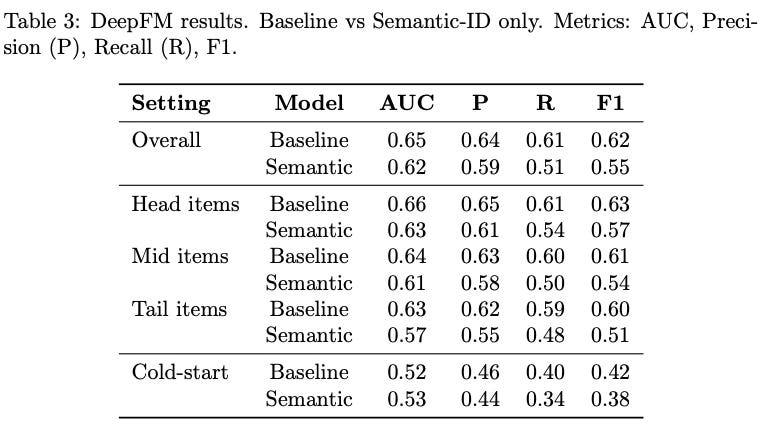
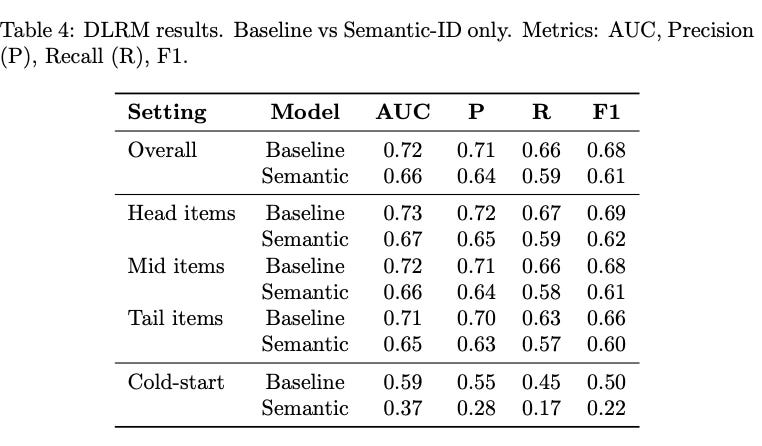
Results reveal a nuanced picture. In WDL, semantic and baseline variants achieve comparable overall performance (AUC ~ 0.74, F1 ~ 0.72). Semantic WDL slightly outperforms baseline on mid-frequency items and on cold-start slices (F1 0.84 vs. 0.79), indicating that semantic IDs can replace metadata-heavy features without loss of accuracy.
In contrast, for DeepFM and DLRM, baseline variants clearly outperform semantic ones. DeepFM with metadata achieves AUC 0.65 vs. 0.62 for semantic, and DLRM baseline reaches AUC 0.72 compared to 0.66 for semantic. Semantic variants in these architectures underperform particularly on tail and cold-start slices. This likely reflects the interaction-heavy nature of DeepFM and DLRM: collapsing item representation to four semantic codes provides insufficient feature diversity for the FM and interaction layers to exploit.
Taken together, the neural experiments show that semantic identifiers can serve as effective item representations in architectures that balance memorization and generalization (e.g., WDL), while interaction-heavy models such as DeepFM and DLRM require either richer semantic coding or hybrid approaches that combine semantic IDs with additional features. These results highlight both the promise and the current limitations of semantic IDs in replacing metadata-rich pipelines.
Another tradeoff here is the complexity of the model. Obviously, there is a cost associated with learning semantic Ids, but the architecture simplifies greatly by using the compressed discrete semantic Ids.

Discussion
Our methodology provides a rigorous framework for fair comparison between explicit metadata features and semantic representations in recommendation systems. By ensuring information equivalence and architectural consistency, we isolate the fundamental question of representation effectiveness, enabling unbiased evaluation of semantic ID approaches and advancing the field toward more principled experimental practices. Our experiments provide several insights into the effectiveness of semantic identifiers (SIDs) as item representations in recommendation systems.
Semantic IDs enable cold-start generalization: Across both matrix factorization and neural models, SIDs consistently outperform item-ID embeddings on cold-start items. While classical MF and ID-based rankers collapse to predicting the global mean for unseen items, Semantic-MF and Semantic-WDL maintain robust predictive power by composing item representations from shared semantic codes. This validates semantic IDs as a practical solution to the long-standing cold-start problem.
Trade-off between accuracy and generalization: Baseline ID-based models achieve lower regression error (RMSE) and higher AUC on head items, reflecting their ability to memorize frequent interactions. However, they fail on sparse slices (tail users/items) and unseen items. Semantic-ID models trade off slight regression accuracy for substantially higher recall and F1, especially in mid/tail and cold-start regimes. This trade-off is valuable in practice, where coverage and diversity are critical.
Architectural dependence: The benefits of semantic IDs are not uniform across architectures. Wide & Deep (WDL), which balances memorization and generalization, shows near parity between baseline and semantic variants, with semantic models excelling on mid-frequency and cold-start slices. In contrast, interaction-heavy models such as DeepFM and DLRM degrade when item representation is compressed to four semantic levels. This suggests that richer semantic encodings or hybrid designs (semantic + selected metadata) may be needed for such architectures.
Parameter efficiency: Semantic models are dramatically smaller: parameter counts are reduced by 3 - 6 times compared to baselines. For example, WDL-Semantic uses 592k parameters versus 2.59M for WDL-Baseline, yet achieves comparable overall performance. This highlights semantic IDs as a parameter-efficient representation that lowers memory footprint and speeds up training.
Practical considerations for deployment: From a systems perspective, semantic IDs reduce dependence on high-cardinality metadata features (brand, category, text hashing), which are often noisy, language-dependent, or expensive to maintain. By replacing these with compact, learned codes, semantic-ID models simplify feature engineering pipelines and provide a consistent representation space across domains. However, care must be taken in choosing the number of semantic levels and codebook sizes to avoid under-representation in interaction-heavy architectures.
Sequential Recommender
Where semantic IDs really shine and provide lot of value is in the sequential recommender tasks. A sequential recommender, like next-item predictor, has to reason over all the items in the corpus to choose the most probable one i.e. the final prediction layer has the dimension equal to number of items in the corpus. This is a major bottleneck in leveraging generative models. Now the cardinality of semantic Ids is much smaller than that of the item corpus, which makes semantic Ids an appropriate choice for sequential and generative tasks.
In a recent work, YouTube showed leveraging semantic Ids learned using RQ-VAE leads to performance gains in recommendation system workflows. Their TIGER model represents a paradigm shift in sequential recommendation systems, moving from traditional embedding-based retrieval to a pure generative approach.
Unlike conventional recommenders that rely on embedding similarity and nearest neighbour search, TIGER frames item recommendation as a sequence-to-sequence generation problem, where the model auto-regressively generates semantic tokens representing the next item a user will interact with. Rather than using arbitrary item IDs, the model employs Semantic IDs - meaningful tuples of discrete tokens that capture item semantics. The model uses a standard Transformer sequence-to-sequence architecture which is trained on flattened semantic token sequence of user interaction history. At inference, the model generates the next-item’s semantic Id. The model generates recommendations through beam search.
We trained a TIGER like model using the 4-level semantic Ids we learned. The training and the evaluation setup is adapted from the TIGER paper - the data is split using leave-one-out protocol where the second last item in the user interaction sequence is user for validation, the last item for test, and all the items before the second for training.
For each user sequence: seq = [item1, item2, item3, item4, item5]
train_items = [item1, item2, item3] # All except last 2
val_target = item4 # Second to last
test_target = item5 # Last item
The semantic Ids are flattened to create a training and evaluation sequence. If the input item sequence is seq = [item1, item2, item3] and the semantic IDs are {item1: [42,203,141,0], item2: [178,208,177,0], item3: [217,69,77,1]}. The flattened input to the transformer model is [42,203,141,0,178,208,177,0,217,69,77,1].
The evaluation is conducted under pure generative setting:
Use beam search to generate K completions of 4 semantic tokens each
Map generated tokens to items (use -1 for invalid mappings)
Calculate metrics over predictions list
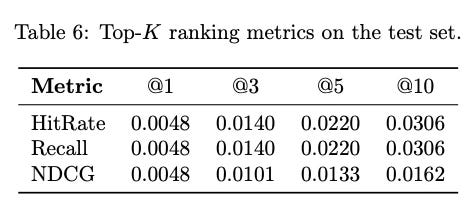
These results are a lower than the ones reported in the TIGER paper which is possibly due to a much longer training loop and more expressive semantic Ids due to more sophisticated methods (VQ-VAE) used. This is something I am exploring currently, will cover it in a future post.
Conclusion
In summary, semantic identifiers are a promising direction for recommendation, offering parameter efficiency and strong cold-start performance. While they are not a universal drop-in replacement for feature-rich rankers, they perform competitively in architectures such as WDL and clearly outperform ID baselines in low-data regimes. It would be interesting to explore hybrid architectures that combine semantic IDs with selected dense or categorical features, as well as methods for learning more expressive semantic codebooks. Most promising application of the semantic Ids is sequential and generative recommendation which has seen a lot of interest lately in conjunction with the modern LLMs.
If you find this post useful, I would appreciate if you can cite it as:
@misc{semantic-ids-recsys,
title={Semantic IDs for Recommendation Systems: A Practical Study
year={2025},
url={\url{https://januverma.substack.com/p/semantic-ids-for-recommendation-systems-88b}},
note={Incomplete Distillation}
}
Thanks Janu.
Thanks for the clear explanation. Could you share some links to the papers which explain Semantic I
D. Thanks Janu.