

LLM-based Cross-encoder for Recommendation Systems

Introduction
Relevance modeling typically involves matching a query (e.g. a user question) to a set of documents (e.g. passages, sentences) by scoring relevance. Two common transformer-based architectures for this task are bi-encoders (representation-based models) and cross-encoders (interaction-based models). They trade off efficiency vs. accuracy. Understanding the differences between these models is crucial for appreciating the challenges and solutions in improving search relevance.
Bi-Encoders (Representation-Based Models)
Bi-encoders are neural network architectures that employ two independent encoders to process a search query and a document into a common dense space. This means the query and the document are processed separately to generate their respective embeddings. Once both the query and the candidate document are embedded, their relevance is scored using vector operations like dot-product or cosine similarity between their embeddings.
These models are typically trained on (query, document) pairs by minimizing a contrastive loss with in-batch negative sampling. This means for a given query, one “positive” (relevant) document and many “negatives” are used as training examples. Bi-encoders are generally efficient for retrieval tasks, making them suitable for initial large-scale candidate generation in search systems. The embeddings for all documents in the corpus are pre-computed and stored in nearest-neighbour search indices.
A significant drawback of this architecture is their limited representational power in capturing the intricate interactions and nuanced semantic relationships between queries and documents because they encode them independently.
Cross-Encoders (Interaction-Based Models)
In contrast to bi-encoders, cross-encoders jointly encode the search query and the document using a single encoder. This often involves concatenating the query and the candidate document with a separator token and feeding the combined input into a transformer model. By jointly processing the query and document, cross-encoders are designed to better capture the complex interactions between them. The model then directly predicts the relevance score.
These models are framed as classification or scoring regression problems and are trained on labeled (query, document) pairs with labeled classes or scores. For example, one can formulate search relevance prediction as a binary classification problem with classes relevant or non-relevant, and the cross-encoder outputs scores for these classes.
While better at fine-grained matching, cross-encoder architecture come with high computational cost and latency during inference. For each candidate document, you must run the full forward pass on the concatenated (query, document) pair. Every query–doc combination is processed from scratch, no pre-computation is possible. Due to this, such architectures are often employed at later stages in the relevance modeling where a smaller set of candidates needs more precise relevance scoring.
LLM-based Cross-encoder in Relevance Modeling
Cross-encoder models with LLM backbones have demonstrated significant improvements in relevance modeling performance. Specific examples include monoBERT (which uses BERT to encode concatenated query-document pairs), monoT5 (using the T5 model to directly output relevance labels), and RankT5 (which optimizes ranking performance with pairwise and listwise ranking loss). RankLLaMA also fine-tunes the LLaMa model with contrastive loss, achieving state-of-the-art performance on public benchmarks.
Recently, I came across the work of Pinterest in using LLM-based cross-encoder for search relevance where they utilized a cross-encoder architecture to predict the relevance of a Pin to a search query. This problem is formulated as a multi-class classification task, categorizing Pins into five ordered relevance levels.

To achieve this, the query text and Pin text are concatenated with a separator token (e.g., [CLS] Query [SEP] Pin Text), and this combined input is fed into a single language model (LLM).
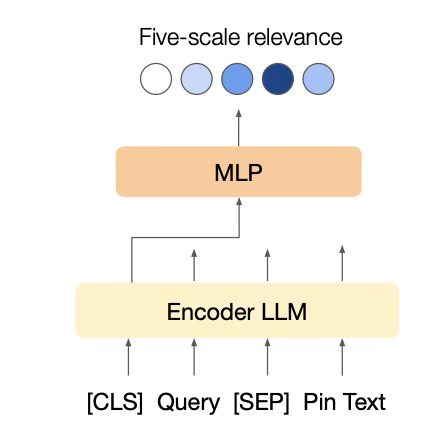
The LLM, which can be an encoder-based model like BERT or a decoder-based model, generates a sentence embedding (e.g., from the [CLS] token or final non-padding token) that is then passed through several fully-connected layers (MLP) to output the five-scale relevance scores using a softmax function. During training, these pre-trained LLMs are fine-tuned by minimizing pointwise multi-class cross-entropy loss. A key aspect of this methodology is the incorporation of carefully designed and enriched text representations for each Pin, which include Pin titles, descriptions, synthetic image captions generated by models like BLIP, high-engagement query tokens associated with the Pin, user-curated board titles, and link titles and descriptions. These rich textual features contribute significantly to building a robust relevance model.
LLM-based Cross-encoder for Recommendation
In my previous post, I talked about search and recommendation as two sides of a coin. Models and techniques from one can be easily applicable to the other. Instead of explicit user-provided queries in search, the implicit user-history is the context for recommendation. Motivated by this, I decided to train a recommender model employing a cross-encoder with LLM-backbone. This complements my previous work on leveraging LLMs for recommendation tasks.
Set Up
As in previous work, we utilize the MovieLens 1M dataset, a well-known benchmark for movie recommendation systems. The dataset contains 1,000,209 ratings from 6,040 users on 3,952 movies, spanning across 18 genres. Each rating is provided on a scale from 1 to 5, with timestamps, enabling temporal sequence modeling.
Problem Formulation: We frame the problem as a multi-label classification (5-way) task, where the objective is to predict the rating a user will provide to a given movie based on their recent viewing history.
The input to the LLM-encoder is the concatenation of the user history and the candidate movie. We use [CAND] as the new token separating the historical movies from the candidate movie.
Last 10 movies are concatenated together separated by ‘|’ to form the input to the encoder.
Experiments
The base LLM model is the pre-trained base Qwen2.5-7B model which is then fine-tuned for our task. With the set up as described above, I conducted multiple experiments.
Only Titles: In this experiment, only titles of the movies are used as history.
Titles + Genres + Ratings: Each movie from the recent user history has the format
Title:::Genre:::Rating.MLP Layers: The classification head of the model is modified to include 2 additional MLP layers before the classification layer. Used the
Title:::Genre:::Ratingformat inputs.Prompt: To take the advantage of the textual nature of the LLMs, used a simple text prompt as input.
prompt = (
"Given a user's past movie ratings in the format title:::genre:::rating. "
"Predict the rating the user will give to the candidate movie. "
"The ratings vary from 1.0 to 5.0.\n"
f"{user_movies}\n"
f"The candidate movie is {candidate}. "
"The rating given by user is?"
)Regression: Since we are trying to estimate the rating the user will give to the candidate, this experiment tried to frame the problem as a regression instead of classification. The model learned by
Evaluation
The evaluation metric is accuracy which measures the overall proportion of correct predictions across classes. In addition, we convert the explicit ratings into an implicit feedback format to evaluate as binary classification:
Ratings ≥ 4 → Positive interaction (Like)
Ratings < 4 → Negative interaction (Dislike)
We use the following binary-classification metrics:
Precision: proportion of predicted “likes” that are actually correct
Recall: proportion of actual “likes” that were correctly identified
F1: Composite of precision and recall.
ROC-AUC: measures the model’s ability to distinguish between positive and negative classes across different thresholds.
Binary accuracy: measures the overall proportion of correct predictions across both positive and negative classes.
Results
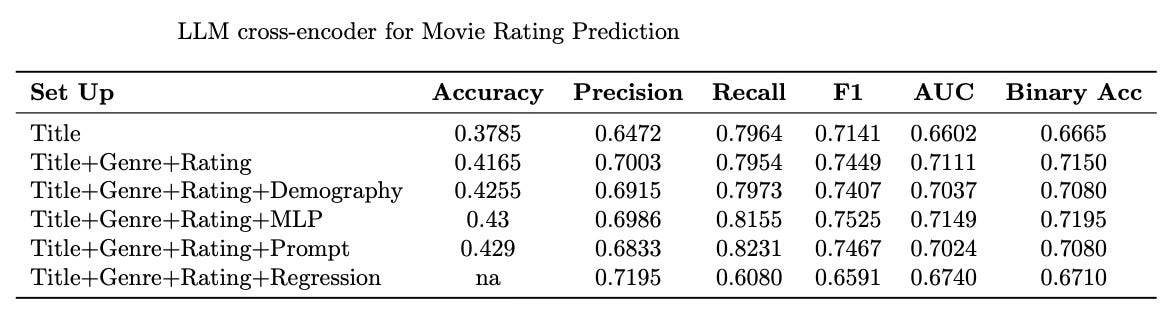
Using only the movie title provides limited predictive power. Adding genres and ratings of the past movies significantly improves performance.
Adding Demographic features to the Title+Genre+Rating setup further improves performance slightly. This and above observation are in line with the Pinterest work where feature enrichment helped boost performance.
Adding an MLP layer gives the highest F1 score (0.7525) and highest Recall (0.8155), with Accuracy at 0.43. This suggests that deeper modeling of inputs improves classification quality.
Prompt-based enhancements give strong Recall (0.8231) and F1 (0.7467), indicating that prompting helps LLMs capture useful decision logic. Though I expected more from prompting as LLM performance correlates to the choice of prompt. Admittedly, no prompt tuning or any careful consideration was employed in this experiment.
Most surprising is that the regression formulation underperforms relative to classification for this task. Again, a carefully crafted setup could have resulted in better performance.
Codes
I used iPython notebooks on Colab for this work. All the notebooks are available on GitHub llm-cross-encoders-for-recsys.
Conclusion
This study explores the effectiveness of LLM-based cross-encoders for recommendation tasks by repurposing architectures traditionally used in search relevance modeling. Inspired by the success of models like monoBERT and Pinterest’s use of rich textual features, I applied similar principles to the MovieLens recommendation setting.
Overall, these experiments reinforce the idea that cross-encoders with LLM backbones—when coupled with carefully crafted input features and lightweight architectural adaptations - can serve as strong models for recommendation. However, the full potential of LLMs in this domain remains under-explored, particularly in terms of prompt design, ordinal-aware loss functions, and integration with larger behavioural signals (e.g., clickstreams or temporal dynamics).
If you find this post useful, I would appreciate if you could cite this work as:
@misc{verma2025llm-cross-encoder,
title={LLM-based Cross-encoder for Recommendation Systems},
author={Janu Verma},
year={2025},
url={\url{https://januverma.substack.com/p/llm-based-cross-encoder-for-recommendation}},
note={Incomplete Distillation}
}